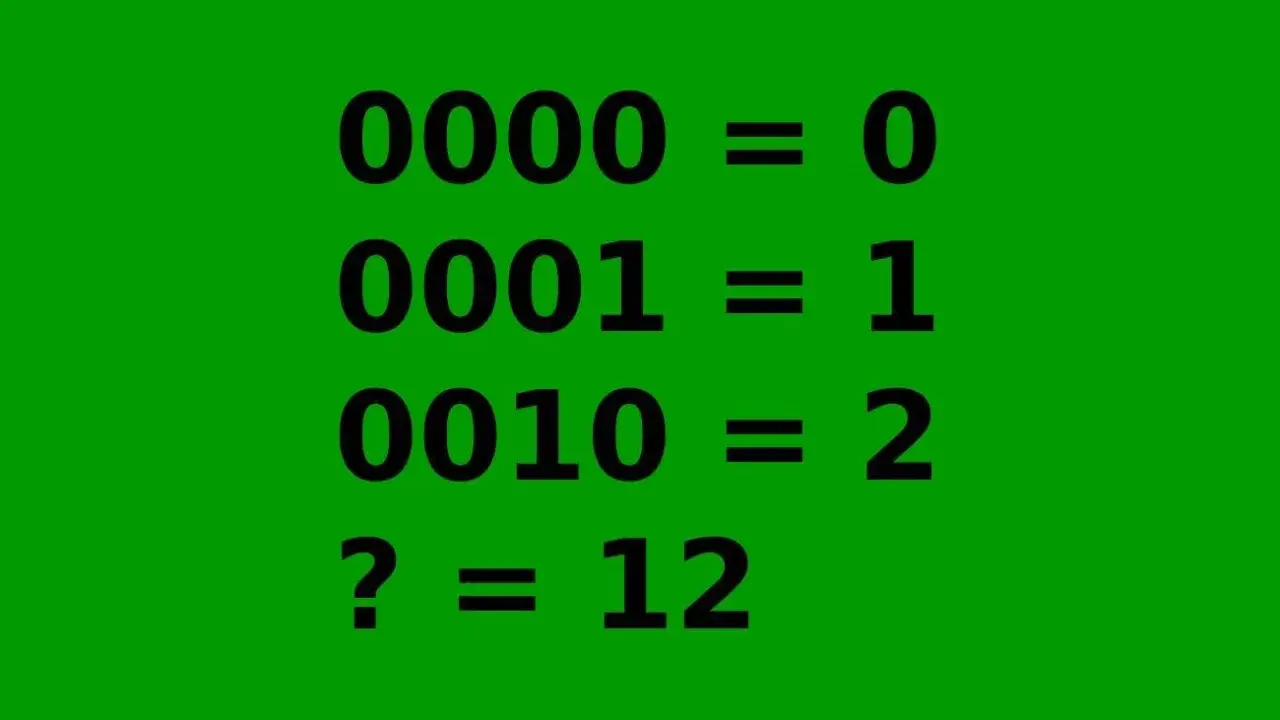
Ten artykuł przeprowadzi Cię krok po kroku przez fascynujący proces zamiany ciągu zer i jedynek, czyli kodu binarnego, na zrozumiałe litery. Dowiesz się, jak komputery "mówią" i jak Ty możesz ręcznie rozszyfrować ich język, poznając podstawowe zasady kodowania znaków. To wiedza, która moim zdaniem jest fundamentem zrozumienia cyfrowego świata.
Jak odczytać litery z kodu binarnego? Kluczowe kroki
- Komputery używają systemu binarnego (0 i 1) do reprezentowania wszystkich danych, w tym tekstu.
- Aby przekształcić binarny kod na litery, należy podzielić ciąg na 8-bitowe grupy (bajty).
- Każdy bajt jest następnie konwertowany na odpowiadającą mu liczbę dziesiętną.
- Liczba dziesiętna jest odnajdywana w tabeli kodowania znaków (np. ASCII, Unicode) w celu identyfikacji litery.
- Standardy takie jak Unicode i UTF-8 są kluczowe dla obsługi znaków narodowych, w tym polskich liter diakrytycznych.
- Istnieją również automatyczne konwertery online ułatwiające ten proces.
Dlaczego komputery "mówią" zerami i jedynkami? Wprowadzenie do języka maszyn
Zastanawiałeś się kiedyś, dlaczego komputery, te niezwykle złożone maszyny, posługują się tak prostym językiem, jakim jest system binarny? Odpowiedź jest zaskakująco prosta i leży u podstaw ich działania. System dwójkowy, operujący wyłącznie na dwóch cyfrach: 0 i 1, jest dla elektroniki idealny. Wyobraź sobie, że komputer to ogromna sieć przełączników. Każdy przełącznik może być albo włączony (co reprezentujemy jako 1), albo wyłączony (jako 0). Ta binarna natura pozwala na niezwykle szybkie i niezawodne przetwarzanie informacji. Niezależnie od tego, czy patrzysz na zdjęcie, słuchasz muzyki, czy czytasz ten tekst, każda informacja cyfrowa, zanim trafi na Twój ekran, jest ostatecznie reprezentowana właśnie w ten sposób.Bit i bajt, czyli cyfrowy atom i cząsteczka informacji
W świecie cyfrowym, tak jak w chemii, mamy swoje podstawowe cegiełki. Pojedyncza cyfra binarna, czyli 0 lub 1, to nasz bit. Można go porównać do atomu najmniejszej, niepodzielnej jednostki. Jednak, aby stworzyć coś znaczącego, potrzebujemy więcej niż jednego atomu. Dlatego w informatyce posługujemy się bajtem, który jest grupą ośmiu bitów. Dlaczego akurat osiem? To historyczna konwencja, która okazała się niezwykle praktyczna. Jeden bajt jest wystarczający, aby reprezentować pojedynczy znak, na przykład literę, cyfrę czy symbol. To właśnie bajty są podstawowymi "cząsteczkami" informacji, które budują cały cyfrowy świat, jaki znamy.
System binarny: Prosty język, który napędza skomplikowany świat technologii
Z pozoru prostota systemu binarnego może wydawać się ograniczająca. Jak to możliwe, że zaledwie dwa stany 0 i 1 są w stanie kodować wszystkie złożone informacje, które widzimy na ekranie, od grafik 3D po strumienie wideo w wysokiej rozdzielczości? Kluczem jest kombinatoryka. Osiem bitów w bajcie pozwala na 256 różnych kombinacji (2 do potęgi 8), co jest wystarczające, aby przypisać unikalny kod każdej literze alfabetu, znakowi interpunkcyjnemu czy cyfrze. Gdy połączymy ze sobą miliony, a nawet miliardy takich bajtów, możemy stworzyć praktycznie każdą cyfrową reprezentację rzeczywistości. To właśnie ta uniwersalność i efektywność sprawiają, że system binarny jest niezastąpionym fundamentem działania wszystkich maszyn cyfrowych.
Klucz do tłumaczenia: Czym są standardy kodowania znaków?
Skoro wiemy już, że komputery "mówią" zerami i jedynkami, pojawia się pytanie: jak te zera i jedynki zamieniają się w konkretne litery, które widzimy na ekranie? Odpowiedzią są standardy kodowania znaków. Można je sobie wyobrazić jako cyfrowe "słowniki" lub "klucze", które przypisują unikalne liczby do każdej litery, cyfry i symbolu. Bez tych standardów, ciąg zer i jedynek byłby dla nas niezrozumiały niczym zaszyfrowana wiadomość bez klucza. To właśnie one pozwalają na spójną interpretację danych tekstowych na różnych urządzeniach i w różnych programach.Poznaj ASCII: Fundament cyfrowego alfabetu dla języka angielskiego
Jednym z pierwszych i najbardziej fundamentalnych standardów kodowania znaków jest ASCII (American Standard Code for Information Interchange). Powstał on w latach 60. ubiegłego wieku i stał się de facto standardem dla komputerów. ASCII pierwotnie używało 7 bitów do reprezentowania znaków, co pozwalało na zakodowanie 128 różnych symboli. Były to podstawowe znaki alfabetu angielskiego (wielkie i małe litery), cyfry, znaki interpunkcyjne oraz kilka znaków kontrolnych. Z czasem pojawiła się rozszerzona wersja ASCII, wykorzystująca 8 bitów, co zwiększyło liczbę dostępnych znaków do 256. Na przykład, wielka litera 'A' jest reprezentowana binarnie jako 01000001, co w systemie dziesiętnym odpowiada liczbie 65. Mała litera 'a' to z kolei 01100001, czyli 97 dziesiętnie. Jak widać, proste i skuteczne ale tylko dla języka angielskiego.
Unicode i UTF-8: Jak komputery nauczyły się polskich liter, czyli "zażółć gęślą jaźń" w kodzie
Wraz z globalizacją informatyki, szybko okazało się, że ASCII jest niewystarczające. Języki takie jak polski, niemiecki, chiński czy arabski, posiadają własne znaki diakrytyczne, symbole i alfabety, których nie dało się zakodować w 256 dostępnych miejscach. Tutaj z pomocą przyszedł Unicode. To uniwersalny standard, którego celem jest przypisanie unikalnego numeru (tzw. punktu kodowego) każdemu znakowi z niemal każdego języka świata. Dzięki niemu, takie zdanie jak "zażółć gęślą jaźń" może być poprawnie wyświetlone na każdym urządzeniu. Sam Unicode jest jednak tylko mapą numerów. Do jego implementacji w plikach i systemach używa się różnych kodowań, z których najpopularniejszym jest UTF-8. To kodowanie jest niezwykle sprytne: jest zmiennodługościowe i co ważne, wstecznie kompatybilne z ASCII. Oznacza to, że znaki z podstawowego zestawu ASCII zajmują w UTF-8 tylko 1 bajt. Natomiast inne znaki, w tym polskie litery diakrytyczne (jak 'ą', 'ę', 'ć'), a także symbole walut czy emotikony, zajmują 2 lub więcej bajtów. Na przykład, symbol euro (€) jest kodowany jako trzy bajty: 11100010 10000010 10101100. To właśnie dzięki UTF-8 możemy bez problemu czytać i pisać w internecie w wielu językach, w tym po polsku.
Różnice, o których musisz wiedzieć: Dlaczego ASCII nie wystarcza?
Kluczowa różnica między ASCII a Unicode/UTF-8 sprowadza się do zakresu obsługiwanych znaków. ASCII, ze swoimi 256 miejscami, jest jak mały, kieszonkowy słownik. Świetnie sprawdza się dla angielskiego, ale całkowicie zawodzi w przypadku języków z większą liczbą znaków specjalnych, takich jak polski, gdzie potrzebujemy 'ą', 'ę', 'ć', 'ł', 'ń', 'ó', 'ś', 'ź', 'ż'. Próba wyświetlenia polskiego tekstu zakodowanego w UTF-8 za pomocą programu oczekującego ASCII często kończy się wyświetleniem tzw. "krzaczków" niezrozumiałych symboli. W przeszłości, dla języka polskiego, używano różnych standardów kodowania, takich jak ISO-8859-2 (zwany też Latin-2) czy Windows-1250. Były to jednak rozwiązania regionalne, które często prowadziły do problemów z kompatybilnością. Na szczęście, dzięki dominacji UTF-8, te problemy są dziś znacznie rzadsze, a UTF-8 stało się globalnym standardem, który moim zdaniem znacznie ułatwił życie wszystkim użytkownikom internetu.
Jak odczytać litery z kodu binarnego? Praktyczny przewodnik krok po kroku
Przejdźmy teraz do sedna, czyli do praktycznej instrukcji, jak samodzielnie przekształcić binarny ciąg znaków w zrozumiały tekst. Ten proces, choć na początku może wydawać się skomplikowany, jest w rzeczywistości logiczny i powtarzalny. Pokażę Ci, jak to zrobić krok po kroku, tak abyś mógł bez problemu rozszyfrować cyfrowe wiadomości.
-
Krok 1: Podziel chaos na porcje grupowanie kodu w 8-bitowe bajty
Pierwszym i absolutnie kluczowym krokiem jest odpowiednie podzielenie ciągu kodu binarnego. Musisz go rozdzielić na równe segmenty, każdy składający się z ośmiu bitów. Każdy taki 8-bitowy segment to jeden bajt, który, jak już wiesz, reprezentuje jeden znak. Jeśli Twój ciąg binarny nie jest wielokrotnością ośmiu bitów, prawdopodobnie masz do czynienia z niekompletnym lub uszkodzonym kodem. Pamiętaj, precyzja na tym etapie jest najważniejsza!
-
Krok 2: Zamiana zer i jedynek na zrozumiałe liczby dziesiętne
Kiedy już masz swoje 8-bitowe bajty, następnym krokiem jest zamiana każdego z nich z systemu binarnego na odpowiadającą mu liczbę w systemie dziesiętnym. Jak to zrobić? Każda pozycja w bajcie ma swoją "wagę", która jest potęgą liczby 2. Licząc od prawej do lewej, wagi wynoszą: 1 (2^0), 2 (2^1), 4 (2^2), 8 (2^3), 16 (2^4), 32 (2^5), 64 (2^6), 128 (2^7). Aby przeliczyć bajt, sumujesz wagi tych pozycji, na których znajduje się cyfra 1. Na przykład, ciąg
01000001oznacza: (0 * 128) + (1 * 64) + (0 * 32) + (0 * 16) + (0 * 8) + (0 * 4) + (0 * 2) + (1 * 1) = 64 + 1 = 65 w systemie dziesiętnym. -
Krok 3: Odszukaj literę w tabeli kodów Twoja cyfrowa "ściągawka"
Po uzyskaniu liczby dziesiętnej dla każdego bajtu, ostatnim krokiem jest odnalezienie tej liczby w odpowiedniej tabeli standardu kodowania. Najczęściej będziesz korzystać z tabeli ASCII lub Unicode/UTF-8. Jeśli, tak jak w naszym przykładzie, otrzymaliśmy liczbę 65, wystarczy spojrzeć do tabeli ASCII, aby zobaczyć, że odpowiada jej wielka litera "A". To jest właśnie ten moment, kiedy z pozornie bezsensownego ciągu zer i jedynek wyłania się zrozumiały znak! Warto mieć taką tabelę pod ręką, gdy ćwiczysz ręczne konwersje.
Przykład w praktyce: Wspólnie rozszyfrujmy słowo "HI" zapisane binarnie
Aby wszystko stało się jeszcze jaśniejsze, przejdźmy przez konkretny przykład. Spróbujmy rozszyfrować proste słowo "HI" zapisane w kodzie binarnym:
- Mamy binarny ciąg:
01001000 01001001 -
Krok 1: Podziel na bajty. Już jest podzielony na dwa 8-bitowe bajty:
01001000i01001001. -
Krok 2: Konwersja pierwszego bajtu
01001000na dziesiętne:- (0 * 128) + (1 * 64) + (0 * 32) + (0 * 16) + (1 * 8) + (0 * 4) + (0 * 2) + (0 * 1) = 64 + 8 = 72.
- Krok 3: Odszukanie 72 w tabeli ASCII: Liczbie 72 odpowiada wielka litera 'H'.
-
Krok 2: Konwersja drugiego bajtu
01001001na dziesiętne:- (0 * 128) + (1 * 64) + (0 * 32) + (0 * 16) + (1 * 8) + (0 * 4) + (0 * 2) + (1 * 1) = 64 + 8 + 1 = 73.
- Krok 3: Odszukanie 73 w tabeli ASCII: Liczbie 73 odpowiada wielka litera 'I'.
-
Podsumowanie: Ciąg binarny
01001000 01001001oznacza słowo "HI". Jak widzisz, z odrobiną cierpliwości i znajomością zasad, możesz samodzielnie rozszyfrować cyfrowe wiadomości!
Najczęstsze błędy i pułapki na co uważać podczas odczytywania kodu?
Chociaż proces konwersji kodu binarnego na tekst jest logiczny, łatwo o drobne błędy, które mogą całkowicie zniekształcić wynik. Jako ktoś, kto wielokrotnie mierzył się z takimi problemami, chcę Cię przestrzec przed najczęstszymi pułapkami. Zrozumienie ich pomoże Ci uniknąć frustracji i zapewnić poprawną interpretację danych.
Błąd "zgubionego bitu": Dlaczego precyzyjny podział na bajty jest krytyczny?
Jednym z najczęstszych błędów, szczególnie na początku, jest nieprecyzyjne grupowanie bitów. Wyobraź sobie, że masz długi ciąg binarny i przez nieuwagę przesuniesz się o jeden bit, dzieląc go na bajty. Nawet jeden "zgubiony" lub źle przypisany bit do sąsiedniego bajtu może całkowicie zmienić wartość dziesiętną obu bajtów, a co za tym idzie wygenerować zupełnie inne, błędne znaki. Dlatego tak ważne jest, aby konsekwentnie i dokładnie grupować bity po osiem. To fundament poprawnej interpretacji i bez tego kroku cała dalsza konwersja będzie bezużyteczna.
Gdy litery zamieniają się w "krzaczki": Problem niewłaściwego standardu kodowania
Pewnie nie raz spotkałeś się z sytuacją, gdzie zamiast polskich liter widziałeś dziwne symbole, tzw. "krzaczki" (ang. mojibake). To klasyczny przykład problemu z niewłaściwym standardem kodowania. Dzieje się tak, gdy tekst, który został zakodowany w jednym standardzie (np. UTF-8, zawierającym polskie znaki), jest próbowany do odczytania za pomocą programu lub systemu, który oczekuje innego standardu (np. czystego ASCII lub ISO-8859-2). Komputer po prostu interpretuje te same ciągi bitów w oparciu o inną "mapę", co prowadzi do wyświetlenia błędnych znaków. Dlatego zawsze, gdy pracujesz z tekstem, szczególnie w różnych językach, kluczowe jest, aby wiedzieć, w jakim standardzie kodowania został on zapisany. To zapewni, że Twój "cyfrowy słownik" będzie zgodny z tym, którego użyto do "napisania" wiadomości.
Droga na skróty: Kiedy warto sięgnąć po automatyczne translatory binarne?
Chociaż ręczne przeliczanie kodu binarnego jest świetnym ćwiczeniem i pomaga zrozumieć mechanizmy działania komputerów, w codziennej pracy często szukamy szybszych i bardziej efektywnych rozwiązań. Na szczęście, nie musimy zawsze polegać na kartce i ołówku. Istnieją narzędzia, które zrobią to za nas.
Czym są konwertery binarno-tekstowe i jak ułatwiają życie?
Konwertery binarno-tekstowe to nic innego jak programy lub aplikacje webowe, które automatyzują cały proces, który przed chwilą omówiliśmy. Zamiast ręcznie dzielić ciąg na bajty, przeliczać każdy z nich na system dziesiętny i szukać w tabeli, po prostu wklejasz binarny kod, wybierasz standard kodowania (najczęściej UTF-8) i w ułamku sekundy otrzymujesz gotowy tekst. Ich główną zaletą jest eliminacja ryzyka błędów ludzkich, które są nieuniknione przy długich ciągach bitów. Są one nieocenione przy szybkich i masowych konwersjach, oszczędzając mnóstwo czasu i wysiłku.
Przegląd darmowych i popularnych narzędzi online do tłumaczenia kodu
W internecie znajdziesz mnóstwo darmowych narzędzi, które pomogą Ci w konwersji binarnej na tekst (i odwrotnie). Wystarczy, że wpiszesz w wyszukiwarkę frazy takie jak "konwerter binarny na tekst online", "translator binarny" czy "binary to text converter". Wiele z nich jest niezwykle prostych w obsłudze, często oferując również możliwość wyboru różnych standardów kodowania (ASCII, UTF-8, itp.). Moim zdaniem, warto mieć takie narzędzie pod ręką, zwłaszcza gdy potrzebujesz szybko sprawdzić krótki fragment kodu lub zweryfikować poprawność swoich ręcznych obliczeń. Pamiętaj jednak, że zrozumienie podstaw, które właśnie zdobyłeś, jest znacznie cenniejsze niż samo korzystanie z automatycznych narzędzi.
Co dalej? Zrozumienie binarnego tekstu to dopiero początek
Gratuluję! Przeszedłeś przez fascynującą podróż od zer i jedynek do zrozumiałych liter. Ta umiejętność to znacznie więcej niż tylko ciekawostka. To podstawa, która otwiera drzwi do głębszego zrozumienia świata cyfrowego. Zrozumienie, jak tekst jest reprezentowany binarnie, to tylko wierzchołek góry lodowej.
Od prostego tekstu po obrazy i dźwięk: Uniwersalność systemu binarnego
Pamiętaj, że system binarny nie służy wyłącznie do kodowania tekstu. Jest to uniwersalny język, który stanowi podstawę reprezentacji wszystkich danych cyfrowych. Niezależnie od tego, czy oglądasz film w wysokiej rozdzielczości, słuchasz ulubionej piosenki, przeglądasz zdjęcia z wakacji, czy grasz w zaawansowaną grę komputerową za tym wszystkim stoją miliardy zer i jedynek. Obrazy są kodowane jako siatki pikseli, gdzie każdy piksel ma swój binarny kod koloru. Dźwięk to sekwencje próbek, a każda próbka to również liczba binarna. Ta uniwersalność systemu binarnego jest po prostu zdumiewająca i moim zdaniem, to właśnie ona czyni go tak potężnym.
Przeczytaj również: System binarny: Rozszyfruj kod maszyn! Prosty poradnik
Gdzie jeszcze możesz wykorzystać swoją nową umiejętność?
Zrozumienie podstaw kodowania binarnego to solidny punkt wyjścia do dalszej nauki. Może okazać się niezwykle przydatne w wielu dziedzinach:
- Programowanie: Zrozumienie, jak dane są przechowywane, jest kluczowe dla efektywnego pisania kodu.
- Informatyka: To fundament, który pomoże Ci lepiej zrozumieć architekturę komputerów i sieci.
- Analiza danych: W niektórych przypadkach, np. przy pracy z protokołami sieciowymi, bezpośrednia interpretacja danych binarnych może być niezbędna.
- Cyberbezpieczeństwo: Umiejętność analizy danych na niskim poziomie jest często kluczowa przy badaniu złośliwego oprogramowania czy odzyskiwaniu danych.